本系列文章将以SAST引擎开发者的视角,讲述笔者如何在实际的漏洞挖掘场景下,利用指针分析等程序分析手段,实现半自动化的Java反序列化利用链挖掘方案。
本文是该系列文章的第一篇,主要讲述必要的概念、核心原理、核心思路和算法。
0x00 引子
在计算机领域中,序列化是将对象或数据结构转换为字节序列以便其可以被存储在磁盘上或通过网络传输的过程,而反序列化则是将字节序列转换回原始对象或数据结构的过程。对于Java而言,根据其序列化数据格式的可读性一般可以分为两大类,第一类是基于bean的,其序列化数据是人类可读的如json、yaml、xml格式,其反序列化过程往往通过getter、setter等方法给实例的属性赋值。第二类是基于反射的,比较典型的包括Java原生序列化、hessian等,其序列化数据为不那么可读的二进制,反序列化过程中,实例属性的赋值往往是通过反射等方式。
一般情况下,对于一个网络服务,如果用户可控的数据最终被视为或封装为序列化数据,并被后端服务反序列化,那么就有可能存在反序列化漏洞的风险。对于Java而言,许多应用或组件历史上都出现过反序列化漏洞,如shiro、fastjson、xstream等。与此同时,反序列化漏洞也往往作为其他攻击手法的一环,像jdbc注入、jndi注入、jmx注入等等,这些攻击手法也能间接触发反序列化操作,从而达到rce等效果。
一个Java反序列化漏洞被成功利用,需要两大步骤:
- 第一步,发现并成功触发反序列化操作
这一步目前业内各大SAST工具已经实现得相当成熟,主要是利用污点分析,判断污点数据是否最终流入反序列化操作的关键参数 - 第二步,发现并构造蕴含足够危害的序列化数据
而这,将是本文重点探讨的问题
0x01 需求分析
我们想要什么?
为了利用一个反序列化漏洞,我们要的最终是payload,也就是序列化数据。为了构造这个payload,一般情况下我们会通过反射等手段事先构造一个 Java实例对象,然后将其序列化。因而我们不禁发问,如何在海量的classpath当中确定要构造什么类型(class)的实例(object)?这个实例的属性又该怎么赋值?
一个反序列化操作能造成rce、文件写、ssrf等效果,究其原因,在于反序列化的过程中往往最终触发了“危险函数”,相对应的,便有一个函数调用栈,我们可以称之为“危险函数调用栈”。根据已有的反序列化payload的构造思路归纳,在“危险函数调用栈”上,往往能够看到一些特定模式的方法(method):对于基于反射的反序列化,会调用名为 readObject (原生反序列化)、readMap(hessian反序列化)等的方法;对于基于bean的反序列化,会调用setter、getter等方法。这些方法用于实例属性的赋值。
因而很容易就能想到,对于payload的构造大致有三步:
- 确定反序列化过程中,实例的创建和属性的赋值是什么逻辑,是否会调用特定格式的方法。为了方便,将这种特定格式的方法称为“起点方法”
- 通过遍历审计所有起点方法,确定该方法是否有可能位于危险函数调用栈中,也就是是否能触发危险函数
- 根据前面的信息,构造Java实例对象,得到序列化数据
步骤1需要专家知识进行归纳,步骤3需要理解代码并精巧地构造。而步骤2,对于人工而言,工作量往往十分浩大,而本文探讨的重点,便在于如何自动化地实现步骤2,也就是通过程序分析的手段,提供精确有效的自动化分析结果,从而降低步骤2和步骤3的总投入。也就是说,payload的构造步骤将转变为:
- 确定反序列化过程中,实例的创建和属性的赋值是什么逻辑,是否会调用特定格式的方法。为了方便,将这种特定格式的方法称为“起点方法”
- 程序分析
- 根据程序分析结果,结合实际代码,构造Java实例对象,得到序列化数据
现在的问题便是,我们想要什么样的程序分析工具?什么样的程序分析结果?
对于该领域的程序分析工具的能力从低到高,大致有以下几类:
| id | 说明 | 备注 |
|---|---|---|
| 类型一 | 搜索classpath中所有起点方法,分析结果为方法列表 | 仅实现起点方法的搜集 |
| 类型二 | 在实现了类型一的基础上,分析结果为不精确的起点方法到危险函数的方法调用路径。 | 其方法调用图的构建往往基于类层次分析,子类的所有方法都会被加入图中,可能造成路径爆炸,生成的无效结果过多。 |
| 类型三 | 在实现了类型一的基础上,分析结果为相对精确的起点方法到危险函数的方法调用路径。 | 用了指针分析等手段实现了call graph的构建,生成的结果较为精确。 |
| 类型四 | 在实现了三的基础上,利用污点分析等手段,确保危险函数被调用的时候,关键参数是用户可控的,还提供具体数据流向,知道这个用户可控的数据是从哪里流进来的,知道整个污点传播的路径。分析结果为更为精确的起点方法到危险函数的方法调用路径 + 具体数据流向 | 更为精确,进一步减少了无效结果。提供的数据流信息,可以用以辅助判断方法调用路径是否有效,更为方便快捷 |
| 类型五 | 实现了四的基础上,同时根据函数调用栈、污点传播数据流等信息,自动化构建一个恶意对象,进行反序列化,自己测试是否成功 | 这个是最为理想的 |
本文接下来将描述,对于Java反序列化利用链的挖掘场景,笔者是如何实现一个类型四的程序分析工具的。
0x02 原理与设计
从上文可知,我们需要的程序分析系统有三个核心模块:
- IR生成模块
将java程序抽象为中间表示形式,基于此做操作,业内有非常多成熟的实现。 - 方法搜寻模块
该模块实现起点方法的搜索功能,其实现较为简单。 - 指针分析模块
具体来说,该模块需要对每一个起点方法进行一次全程序分析,使用指针分析和污点分析算法,每一个全程序分析都需要给出两个分析结果文件:
1. 函数调用栈结果。其内容是起点方法到危险函数的函数调用栈,且危险函数的关键参数可控。
2. 污点传播数据流结果。其内容是污点数据的传播流向,即用户可控的污点数据从哪个变量流经哪些变量,最终进入哪个变量。
接下来重点讲述指针分析模块的原理与设计
总设计的核心要素
指针分析模块是关键逻辑的处理模块,对于该模块的运行逻辑和具体算法的设计,有如下几个核心要点:
一、采用指针分析和污点分析相融合的全程序分析算法。
二、特殊的污点传播规则:
- 所有构造方法都是Arg-to-base类型的污点传播方法。
- 对于实例属性读语句,如y = x.f,如果基变量x被污染,那么左值y被污染。
- 对于数组元素读语句,如y = x[i],如果基变量x被污染,那么左值y被污染。
- 所有实例的getter方法都是Base-to-result类型的污点传播方法。
- 进行全程序指针分析时,起点方法的所有参数和
$this变量都视作被污染。
三、修改了方法调用的处理方式,改为采用指针分析和类层次分析混合:
如果基变量被污染,就将基变量对应类的所有子类中声明的方法全部视为可能调用的方法。否则根据抽象堆对象的具体类作方法解析。
四、通过调用点敏感技术记录输出函数调用栈
使用k-call技术在提高指针分析精度的同时,保存函数调用栈,不必遍历call graph,不需要用到图搜索算法。
五、增加多级起点方法搜寻,提高整体链路搜寻的效率和精度
对于基变量被污染,且所有参数被污染的函数调用,可以将其所调用的函数就作为二级起点方法,以之作为起点方法再度调用全程序指针分析,进行链路挖掘。
具体设计思路和基本原理
接下来的内容会介绍使用的一些关键技术以及基本概念,笔者希望尽量写得简单易懂一些,避免晦涩到劝退读者。如果想要阅读了解更为专业更为学术的内容,可以参考:谭添,马晓星,许畅,马春燕,李樾.Java指针分析综述[J].计算机研究与发展,2023,60(02):274-293.、
Grech N, Smaragdakis Y. P/taint: Unified points-to and taint analysis[J]. Proceedings of the ACM on Programming Languages, 2017, 1(OOPSLA): 1-28.,
南京大学的程序分析公开课 以及 Tai-e的指针分析与污点分析源代码
指针分析与污点分析原理
当我们得到一个起点方法,比如说HashSet的readObject方法: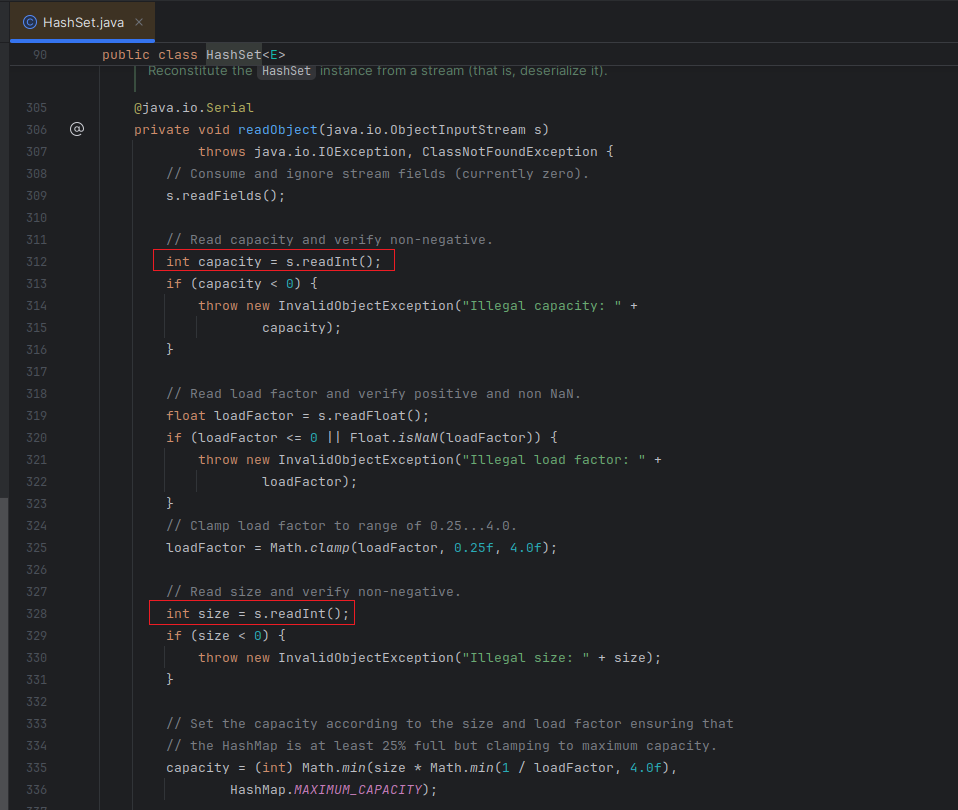
从代码审计工程师的视角正向审计,我们首先会思考这个函数运行起来之后,都有哪些实例(object)被创建了出来,这些实例可能是通过明显的new语句被创建的,也可能是作为某个函数调用的返回值被创建了,同时我们会思考这些运行时存在的实例是否完全由用户控制,或者封装了用户控制的数据。
随后,我们会在idea里面点点点,查看被调用的各个函数,试着在脑中模拟程序运行时的调用栈,并最终确定是否有一些有趣的函数被调用。同时,我们也会关注实例在变量之间的流动,比如通过赋值语句,我们想象一个实例从右边的变量流动到了左边的变量,通过函数调用语句,一个实例从函数调用的传参,流动到了函数声明时的形参当中,正是通过想象这样的实例流动,我们从而确定是否有用户可控的数据最终流动到了有趣函数的关键参数当中。
指针分析本质上就是完成了上述的工作。”指针分析“当中的“指针”二字,可以简单地理解为变量,指针分析可以简单地理解为:分析实例是如何在整个程序的所有变量当中流动的。指针分析最核心的结果是一个图,名为Pointer Flow Graph ,其中的节点(node)是程序当中所有的变量,而有向边(edge)代表着实例(object)的流向,节点(node)的属性集(attributes)当中,有一项Points To Set ,表示实例集,也就是所有流经过该变量的实例的集合。
对于常见的赋值语句,处理规则如下:
- 对象创建语句(New),如x = new X(),会抽象一个实例,将其加入x变量的实例集。
- 复制语句(Copy),如y = x,x的实例集中的所有实例会加入(add)y的实例集。
- 强制类型转换语句(Cast),如y = (Type) x,,x的实例集中的所有实例会加入(add)y的实例集,并且这些实例的类型(class)将被改为Type。
- 静态字段读取语句(StaticLoadField),如 y = T.f,直接将T.f的实例集中的实例都加入到y的实例集。
- 静态字段赋值语句(StaticStoreField),如 T.f = y,直接将y的实例集中的实例都加入到T.f的实例集中。
- 字段读取语句(LoadField),如 y = x.f,需要遍历x的实例集,假设其中一个实例是o,那么就要直接将o.f的实例集中的实例都加入到y的实例集中。
- 字段赋值语句(StoreField),如 x.f = y,需要遍历x的实例集,假设其中一个实例是o,那么就要把y的实例集中的所有实例都加入o.f的实例集中。
- 数组元素读取语句(LoadArray),如 y = x[i],一般情况下,指针分析当中会将这种情况视作一种特殊的字段读取语句(LoadField),也就是看作y = x.arr。
- 数组元素赋值语句(StoreArray),如 x[i] = y,一般情况下,指针分析当中会将这种情况视作一种特殊的字段赋值语句(StoreField),也就是看作x.arr = y
而对于函数调用语句,则需要特别讨论。
从上面的规则不难看出,一个抽象的实例想要被创建,代码当中必须得有New语句,而污点分析,其实质就是研究员额外加了一个关于抽象实例创建的规则:
- 函数调用语句(Call),如 capacity = s.readInt(),直接抽象一个实例,将其加入capacity变量的实例集,且给这个实例打一个标签,称之为污点对象或污点数据,同时称capacity变量被污染了。
为什么要额外加这个规则呢,理由很简单,就是研究员知道s.readInt()一定会返回一个 Integer实例,而且实例解析自序列化payload,用户可控。这么一来当指针分析结束的时候,如果我们看到感兴趣的函数的关键参数被污染了,那么就可以断言,有一些用户可控的数据流入了关键参数当中,从而显而易见地得出结论:通过一个反序列化操作,能够触发一个我们感兴趣的函数被调用,而且关键参数用户可控。
在实际的分析中,研究员往往会增加多个类似上述的抽象实例创建的规则,比如,在java原生反序列化的场景下,readUTF()、readObject()、readInt()等函数调用时,左值的变量都会被污染,这些函数每一个都对应一个关于抽象实例创建的规则,我们将无条件污染左值的这些函数称为Source。
而对于我们感兴趣的函数的关键参数,我们称之为Sink。
函数调用语句的处理
jvm有多态的特性,也就是继承自相同父类的子类(class),可能同时重写(override)了父类的某个方法(method),最经典的就是所有类都继承自java.lang.Object,而有许多类都同时实现了自己的 java.lang.String toString() 方法。
在指针分析程中,如果过遇到了一个静态方法调用(invokestatic),如y = T.method0(a),首先需要找到T类的静态方法method0声明的位置,然后将a的实例集的所有实例加入method0声明的位置的形参的实例集当中,再然后将method0声明的函数体中,最后的return语句所return的那个变量的实例集的所有实例计入y的实例集中。
但是由于多态的特性,确定所调用的方法的声明位置并不总是容易。在java当中,方法调用有以下几种类型,为了确定方法声明位置,需要采取不同策略:
- 静态方法调用(invokestatic),不存在多态问题,直接就能确定。
- 特殊方法调用(invokespecial),用于调用构造函数(
<init>)、私有方法(private)和父类方法(super),不存在多态问题,直接就能确定。 - 实例方法调用(invokevirtual),如 y = x.method0(a) ,x称为基变量(base)。考虑到多态,仅仅根据这个语句很多时候没法推测唯一确切的方法声明位置,因为各个子类都有可能,需要做特殊处理。
- 接口方法调用(invokeinterface)。如 y = x.method0(a) ,x称为基变量(base)。考虑到多态,仅仅根据这个语句很多时候没法推测唯一确切的方法声明位置,因为各个子类都有可能,需要做特殊处理。
在java反序列化利用链挖掘的场景中,对于invokevirtual和invokeinterface,笔者想到采用实例类分析与类层次分析相结合的方式,伪代码如下:


对于invokevirtual和invokeinterface,首先根据Pointer Flow Graph,获取基变量所有的实例,然后判断其中是否存在污点对象,如果存在污点对象,就将基变量对应类的所有子类中声明的方法全部视为可能调用的方法。
这样处理的原因在于,在反序列化的时候,一般情况下一个污点对象实际上往往被赋值到实例的属性,污点对象指用户可控,而用户可以控制这个属性为任意声明的子类,这也就意味着在方法调用的时候,也可以调用任意子类的同名方法。
而如果不存在污点对象,则将实例对应的类所声明的方法视为调用的方法。
污点传播原理
上文已经大致描述了所运用的基于指针分析的污点分析的基本原理,为了让其运行得当,还需额外添加多个关于抽象实例创建的规则。除了上文提到的Source之外,还有一类和抽象实例创建相关的规则,比如:
- 函数调用语句(Call),如
y = x.<java.lang.String: java.lang.String concat(java.lang.String)>(a),如果x被污染,则直接抽象一个污点对象,将其加入y变量的实例集 - 函数调用语句(Call),如
x.<java.lang.String: void getChars(char[],int)>(a,b),如果x被污染,则直接抽象一个污点对象,将其加入a变量的实例集
额外加这个规则的原因是,考虑到在经过一些函数调用之后,基变量或传参变量的实例可能会被封装或分解为新的实例,而如果原实例为污点对象用户可控,那么新的实例一定程度上也是用户间接可控的。
新的污点对象由于旧的污点对象的存在而被创建,这称之为污点传播,我们将与之相关的函数称为污点传播函数(Transfer)
污点传播函数有三类: - Base-to-result。如果基变量被污染,那么左值被污染。
- Arg-to-base。如果参数变量被污染,那么基变量被污染。
- Arg-to-result。如果参数变量被污染,那么左值被污染。
比较通用的污点传播函数包括String相关的读写转换、stream的读写、加密解密、collection相关的读写等等。除此之外,针对java反序列化利用链挖掘的场景,笔者基于个人经验,设计了如下五条污点传播的规则:
- 所有构造方法都是Arg-to-base。
- 字段读取语句(LoadField),如y = x.f,如果基变量x被污染,那么左值y被污染。
- 数组元素读取语句(LoadArray),如 y = x[i],如果基变量x被污染,那么左值y被污染。
- 对于invokevirtual和invokeinterface,所有getter方法都是Base-to-result。
- 进行全程序指针分析时,起点方法的所有参数和
$this变量都视作被污染。
函数调用栈的记录
指针分析结束,通过一个反序列化操作,能够触发一个我们感兴趣的函数被调用,而且关键参数用户可控,根据Pointer Flow Graph,我们可以利用图算法,得到污点传播数据流结果,那么对于函数调用栈又该怎么获取呢?
一般情况下,在指针分析的过程中,每一次处理函数调用语句,都能得到一个函数调用的关系,将这个关系以图的形式保存下来,可以得到一个函数调用图,我们可以直接通过这个图,运用图算法来找到起点方法到我们感兴趣的函数之间的调用路径。
但是笔者在实践中,运用了一个更简单的获取函数调用栈的方法:利用调用点敏感(call-site sensitivity)技术,每当处理到一个函数调用时,都会绑定当前的函数调用栈,这么做有诸多便利:
- 提高指针分析的精度
- 记录函数调用栈
- 在分析过程中记录并控制分析的深度
指针分析的效率和精度受到上下文敏感策略、堆对象抽象策略、流敏感策略、分析范围等因素的影响,其中影响最大的因素是上下文敏感策略。上下文敏感是指在指针分析过程中考虑函数调用的上下文信息,从而区分不同调用上下文下的函数行为。相比于上下文不敏感策略,上下文敏感策略能够提高指针分析的精度。上下文敏感技术有多种,其中调用点敏感(call-site sensitivity),又称调用串敏感(call-string sensitivity)或k-call,该策略将上下文(context)定义为一串调用点,也就是函数调用栈。
多级起点方法链路挖掘
上文大致描述了指针分析模块的运作原理和实现细节,但是在实践当中会发现由于仅仅通过上述方案还不够完备,经常遇到路径爆炸等问题,导致函数调用栈的深度屡屡受限,从而挖不到理想的链子。笔者在分析和尝试之后,设计了多级起点方法链路挖掘的方案,一定程度上缓解了”够不着“的问题。
在指针分析过程中,我们需要关注记录如下两种函数调用:
- 基变量的声明类为
java.lang.Object且非<init>的 invokevirtual - 任何invokeinterface
在指针分析结束之后,需要便利所有这些记录下来的函数调用,看一下是否满足:基变量被污染,且所有参数被污染,如果是,那么所调用的函数就可以作为二级起点方法,可以以这些方法作为起点方法再度调用全程序指针分析,进行链路挖掘。
以原生反序列化为例:
- 以
java.util.PriorityQueue的readObject为起点方法,能够发现二级起点方法<java.util.Comparator: int compare(java.lang.Object, java.lang.Object)>。也就是说从这个readObject可以最终调用任意一个类型的对象的 compare方法,且两个参数完全可控。 - 以
javax.management.BadAttributeValueExpException的readObject为起点方法,能够发现二级起点方法<java.lang.Object: java.lang.String toString()>。也就是说从这个readObject可以最终调用任意一个类型的对象的toString方法。 - 以
java.util.HashSet的readObject为起点方法,能够发现二级起点方法<java.lang.Object: int hashCode()>
也就是说从这个readObject可以最终调用任意一个类型的对下给你的hashCode方法
整体工作流程
整体的工作流大致如下: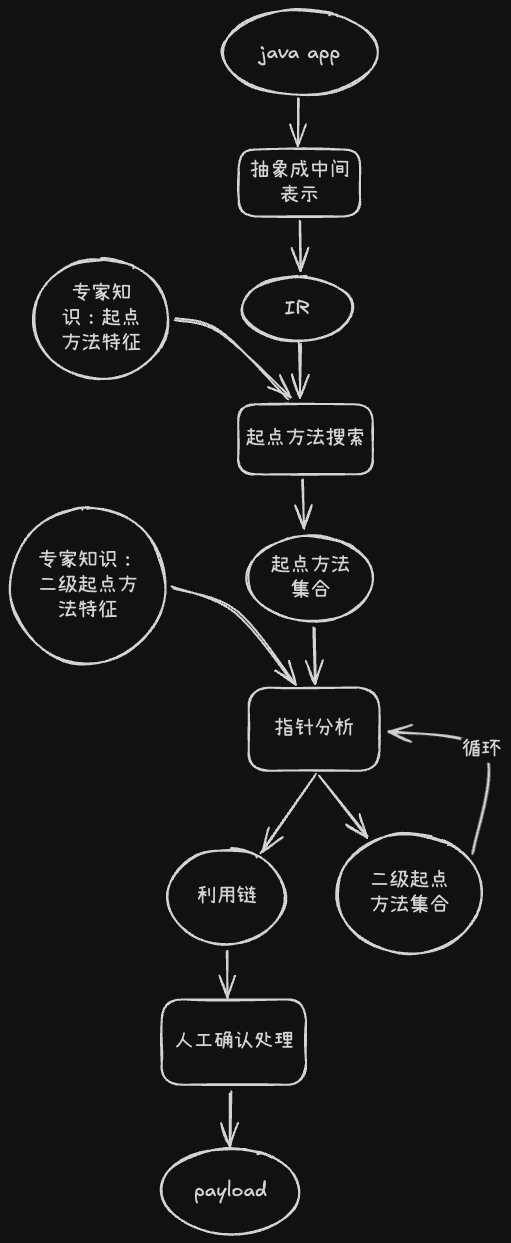
- IR生成。IR生成模块工作,将classpath中所有的类处理为中间表示,最终得到一个IR数据库
- 起点方法搜寻。把所有readObject查找出来,这些都是下一步全程序分析的入口。
- 二级起点方法搜寻 + 利用链搜寻。遍历每一个readObject,将其作为全程序分析的入口,进行限制时间限制深度的指针分析+污点分析,最终得到可能的危险函数调用栈 + 污点数据流 + 二级起点方法列表
- 人工核查程序分析结果
- 起点方法搜寻。把所有二级起点方法查找出来,这些都是下一步全程序分析的入口。
- 三级起点方法搜寻 + 利用链搜寻。…………
如此反复,最终人工核查程序分析结果,得到可成功利用的链子,并构造可利用的payload
0x03 总结
本文的主要内容为笔者对java反序列化利用链挖掘的思考,以及对应的程序分析工具的基本原理和实现思路,该工具的核心为基于多级起点方法的指针分析系统。之后的文章笔者将对工具的实现细节做进一步分享,并公开一些指针分析与漏洞挖掘的实践案例。